
テキストファイル。世界中のプログラマすべてが使う、必須のファイル形式です。
単純そうに見えるテキストファイルですが、仕様を知らないがゆえに起きるトラブル、意外とあります。
テキストファイルの大事な知識、おさえておきましょう。
テキストファイルとは?
テキストファイルとは、文字データだけで構成されるファイルです。
テキストファイル最大のメリットは、人の目で見て中身分かること。テキストエディタなどで閲覧でき、編集したりもできます。
反対は「バイナリファイル」。画像ファイルとかプログラム実行ファイルですね。これらはエディタで見たところで理解できません。
そもそも「ファイル」とは?
そもそも「ファイル」が何かというと、数字の並びを記録したものです。
こんなテキストファイルがあるとします。
Hello
人が見れば”Hello”という文字ですが、実際のファイルは、このような数字の並びで記録されています。

赤枠が、ファイルの中身です。48,65,6C…が、それぞれひとつの数値(16進数で表示)。
ここでは、5個の数値が並んでいますね。この1個1個の領域をバイトといいます。
1つのバイトには、00~FFの数値が入ります。10進数でいえば、0~255 の範囲。
ファイルのサイズは5バイト、ということになりますね。
このように、ファイルの中身を数字で表示することを、「バイナリで表示する」といいます。バイナリを表示できるツールは各種あります。ここではWindows PowerShell の Format-Hex コマンドで出力しています。
文字を表す数値、文字コード
“Hello”という文字、実際のファイルの中身は5個の数字。
となれば、文字と数字が対応している、と想像できますね。
この、文字に対応した数値の定義を、文字コードと言います。
ASCIIコードで文字を数値に
“Hello”という5個の文字、ファイルサイズが5バイト、であれば、1つのバイトが1つの文字を表していそうですね。
この、文字と数字の対応(=文字コード)の決まりが、ASCIIコードです。読みは「アスキーコード」。
ASCIIコードでは、”A”→65、”1”→49、”%”→37、といった具合の対応が決められています。
これは国際的な規格なので、万国共通に通用します。
日本語は1バイトで表現できない
ASCIIでは、1バイトの数値と対応しています。しかし、1バイトは0~255までしかありません。
ここで疑問。じゃあ、1,000文字以上ある日本語の場合はどうなるの?
実際試してみましょう、こんなテキストファイルなら?
こんにちは
中身をみてみます。

なんか増えました。数えると、15バイトあります。
察しはつきますね。日本語の場合は、複数のバイトで1文字を表現するのです。
うえの例だと、3バイトで1つの文字、を表しています。
日本語の文字コードには複数ある
英字や数字は、ASCIIコードという規格の文字コードがあります。
では、日本語の場合の、文字コードは?
当然、文字コードの定義はあります。
しかしやっかいなのは、日本語の文字コードは、規格が複数あるのです。
このような文字コードが存在します。
- Shift-JIS
- EUC
- UTF-16
- UTF-8
同じ「こ」という文字であっても、文字コードにより対応する数値が違います。
例えばテキストファイルを、EUCとして保存して、UTF-8として開く。こうすると全然違う文字として表示されてしまいます。
これが、文字化け、と呼ばれるものの、正体です。
今の時代は、”UTF-8″一択
ひと昔前までは、様々な文字コードが入り乱れて、文字化けという現象が頻発していました。
ただ、覚えておきましょう、
いまの時代、選択すべき日本語文字コードは、 “UTF-8” 一択です。他はまず使いません。
様々なツールやアプリケーションも、UTF-8に統一する方向で動いています。
根深く残るOSの問題
プログラミングで文字コードが問題となるのは、たいてい、OSの違いによるところです。
- Windowsではかつて、Shift-JISが標準文字コードであった
- MaxやLinuxは、UTF-8を標準としている
ただ最近では、Windowsも UTF-8 が標準となってきたので、問題は起こりにくくなっています。
UTF-8のBOMはいらない
UTF-8を釣っていると、たまに「BOM付き」「BOM無し」という言葉を、聞くことがあるかもしれません。Windowsメモ帳の保存オプションにもあったりします。
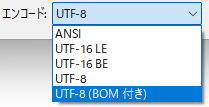
こんにちはファイルを、BOM付きで保存した結果

BOM付きの場合、先頭に3つの数字が追加されます。
詳しくはしらなくてよいです。これだけ覚えてください。
BOMはいりません。必ず、BOMなしUTF-8 で保存してください。
意外とやっかい、空白の話
つぎは空白の話です。人の目には「空」としか見えなくても、実は色々な種類があるのです。
半角スペースと全角スペースの違い
キーボードの一番下の長いキーのやつ。「スペース」あるいは「ホワイトスペース」とも言われます。
スペースには、「半角スペース」と「全角スペース」があります。半角スペースは英語入力のとき、全角スペースは日本語入力のときに入力できます。
覚えておきましょう。全角スペースと半角スペースは、文字コードが明確に違います。例でみましょう。
半角スペース
Hello World

全角スペース
Hello World

全角スペースだと、3バイトに増えましたね。
大事なのはただひとつ、プログラミングでは全角スペースを使うな、です。
スペースはいろいろな区切り文字として使います。プログラムコードを書くとき、データをテキストファイルに出力するとき…。
人が見て空白に見えたとしても、コンピューターは、全角スペースを空白とみなしません。
特別な理由がない限り、スペースは必ず半角にしましょう。
タブとスペースの違い
空白について、プログラマーにはもうひとつ、「タブ」か「スペース」か問題があります。
プログラムコードを書く時の、字下げ(インデント)を、タブとするかスペースとするか。
例えば以下のC言語コード、途中で4文字分や8文字分の空白があるところ、がインデント。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
int main() {
int target, guess, attempts = 0;
srand(time(NULL));
target = rand() % 100 + 1; // 1から100までのランダムな数を生成
printf("1から100までの数を当ててください!\n");
do {
printf("予想を入力してください: ");
scanf("%d", &guess);
attempts++;
if (guess > target) {
printf("もっと小さい数です\n");
} else if (guess < target) {
printf("もっと大きい数です\n");
} else {
printf("正解です!\n");
printf("正解までの試行回数: %d\n", attempts);
}
} while (guess != target);
return 0;
}インデントはタブかスペースか、これはプログラムを書くときの規約によるので、その規約に従いましょう。
ただ現在の主流は、スペースによるインデントです。「2文字分」か「4文字分」かという違いがあったりしますが。
なお、VisualStudioCodeなどの最近のプログラミングエディタには、たいていタブスペース相互変換の機能がついています。間違えたとしても簡単に直せます。
なかなかやっかい、改行コード
次は、問題の多い改行コードの話です。これも人の目には見えない違いがあります。
改行コードとは
以下の2つのテキストファイル、中身はどう違うでしょうか?
HelloWorld
Hello
World
みてみましょう


2段に分かれているほうは、0D 0A が追加されました。これが改行コードです。
0Dも0Aも、普通の文字ではなく、改行という意味を表す制御コードです。
0D,0Aは、それぞれ次のように呼ばれます。
- 0D:キャリッジリターン CarriageReturn:CR、文字であらわすと\r
- 0A:ラインフィード LineFeed:LF、文字であらわすと\n
この2文字の改行コードを合わせて、CRLF と呼んでいます。
Windows、Mac、Linux の違い
さて、上の話は、Windowsのメモ帳で書いたときの話です。
これがLinuxやMacだと、話が違ってきます。以下は、Linux の Vim で保存した時の内容です。

Linuxでは、改行コードが0A、つまりLFのひとつだけになっています。
同じ改行でも、WindowsではCRLF、MacやLinuxではLFとなってしまう。これが改行コード問題です。
例えば、
- Linuxサーバから、自分のWindowsPCにテキストデータファイルを持ってくる
- メモ帳で編集する
- Linuxサーバに再度アップする
とすると、
 ベテランさん
ベテランさん改行コード変わってるじゃないかーーーーー!
といった問題が起こったりします。※注:現在のメモ帳は改行コードを保持します。
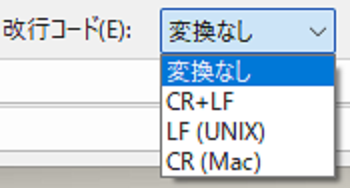
ちなみにWindowsでも、フリーのテキストエディタなどでは、改行コードの指定ができます。
例えばサクラエディタなら、保存時に改行コードが指定できます。
※注:昔のMacは改行コードCRでした。いまはiOSがLinuxベースなのでLinuxと同じです
ところがWindows標準のメモ帳だと、普通に保存するとCRLFになります。
なのでメモ帳で編集していたりすると、
ベテランさんプログラミングでメモ帳を使うなぁーーーーー!
と怒られます。
プログラムを書くときはちゃんと、プログラミング用のエディタを使いましょう。
一番有名なのは、Visual Studio Codeですね。今はプログラマーの必須ツールと言えるでしょう。
プログラミング用エディタなら、OSの影響受けることなく改行コードを保持してくれます。
まとめ
テキストファイルの話は、プログラミングに慣れると、自然に身についてきます。
でも初心者の頃は、なかなかこの辺り知らないことも多いでしょう。
なにかトラブルが起きた時、参考にしてみてください。
コメント